

Industrial consumers have more access to data than ever before, but what to do with it? Can advancements in technology really make us better tomorrow than today? This thought-provoking article will introduce a concept to building context into data to ultimately achieve intelligent actions or recommendations from computing systems. While our example will hit home for water treaters, the concept behind this process and accompanying example is completely transferrable to any industrial application.
Using data to achieve intelligent action is certainly not a new concept and it is getting a lot more attention in the technology market these days. I started this series of articles to help the general, non-technology oriented individual to better understand the capabilities of technology and how it can help all of us be better. This article will expand on the same intention with a focus on closing the gap in the understanding of how technology can be used to analyze data and turn it into action to provide real, monetized benefits to businesses and industries. If this sounds similar to what you have seen being marketed as artificial intelligence (AI) or machine learning (ML), that’s because it is. Both AI and ML refer to a situation when a computer is analyzing data and information to either perform an action or provide suggestions to humans to act on something. In other words, turning data into action.
Contrary to what Hollywood might have us believe, AI, in current terms, does not imply that computers are programming themselves. In reality, AI is an extension of ML applying additional computation to contextualized data to act or make recommendations in a similar fashion to how a human might. This is not to say that AI is capable of replacing human thought, but it is to say that AI can greatly benefit all of us by processing tremendously more information than our human brains can.
The evolution of AI and ML in current terms began from movement towards “big data” about six to seven years ago. Essentially our culture has progressed to rely more and more on technology, the information now being collected produced tremendous amounts of data. We needed practical ways to begin processing the massive amounts of data into performing intelligent actions; hence the evolution of technology to ML and AI. Chances are that you have already experienced ML and AI technologies in your daily life. ML and AI algorithms are already impacting our lives with features such as steaming television show recommendations, recommendations from your favorite technology persona, and smartphone application ease-of-use features.
To understand how we can turn data into action, we need to first add context to the data. Contextualizing data is the process of adding information and knowledge to build a foundation to make logical decisions. Data on its own provides little value to us. Providing context gives us a foundation to make observations about data as it’s received and ultimately draw conclusions from it. As humans, we instinctively apply knowledge and information to data continuously to make decisions. Technology has given us the opportunity of imparting the information and knowledge on to computing systems to now provide action without the need for human processing of data. The result is that humans can focus on developing the key information and knowledge that is crucial to making things work better rather than spend valuable time “crunching” data. It’s also for this reason that AI and ML are not trimming the workforce, but rather creating opportunities for new job functions.
Practical Application of Contextualizing Data for an Industrial Application
As the computing systems that process data for action require context, provided by people, it’s important to carve out a process for defining the context. I am going to introduce a process that stakeholders can take to organize their thoughts in building out an application “ecosystem” with context. This process includes a distinction between information types, see Figure 1. Microlayer information consists of the information that makes up a particular data source or “tag.” This might include meta information about the data source’s manufacture, installation point, or runtime along with the specific real time data points it might provide. The macrolayer provides context regarding how the ecosystem is connected and interacts; both in the control boundaries and outside into operations. Macrolayer information might include data source dependencies and interconnections, definition of key performance indicators, and control scenarios.

5 step process to building the application ecosystem:
- Define the application
- Identify the data sources
- Identify data source microlayer information
- Identify general macrolayer relationships in application
- Define the detail of each relationship interdependency.
Step 1: Define the application
As you embark on building an information ecosystem around the application, it’s important to break down the applications into small components of a much larger process. The complexity of defining the ecosystem for even a very simple application can be high. If you define the application too wide the amount of information to process might become counterproductive. Prior to defining your specific applications, you may want to break down your process into as many separate and distinct applications as possible. For many industrial consumers, a process is made up of multiple unit operations. A unit operation may have multiple applications or may constitute an application in itself. Another consideration is to generalize your applications where possible. There are likely varying use cases for a single application. This will allow you to utilize either the same or similar context for the application ecosystem in multiple use cases. Consider your process(es) carefully.
Application definition guidelines:
- Be careful to not define your application too widely
- Generalize your application where possible.
For our example, we will take a very basic water disinfection application. By nature, water solutions will have a potential to grow biological material that can cause personal harm or damage assets. Feeding a disinfectant to the water manages the biological growth. However, many disinfectants are harsh chemicals that can also cause harm to humans or damage assets if dosed improperly. This requires a controlled balance in the application’s ecosystem. There are many, far more specific applications within the disinfection realm; which means we can generalize and gain more use from our work.
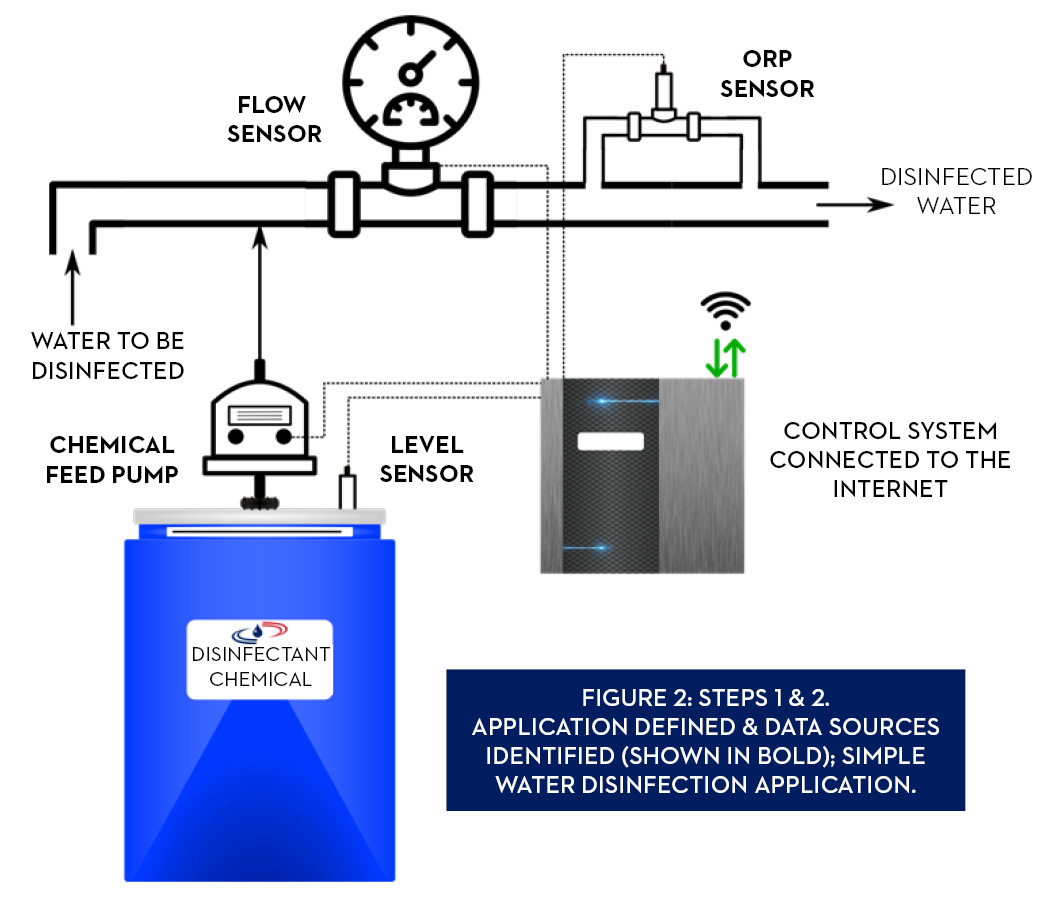
Step 2: Identify all data sources
See the Figure 2 to identify the basic data sources for both monitoring and control in our example application.
Step 3: Building Information at Microlayer – Example: ORP
Traditional control systems bring in only the data required to make an acute control change. Utilizing digitally enabled sensors allow for expanded access to data that can be utilized to apply intelligence to the system. Intelligent tracking can be used to monitor sensor replacement, calibrations, and even identify if the probe is becoming fouled and requires a cleaning vs replacement.
Tying back to our water disinfection example, Oxidation Reduction Potential (ORP) is a measurement used by water treaters to indicate the oxidizing ability of a water solution; often used to indicate the water’s ability to reduce biological content. Utilizing a digitally enabled ORP sensor can enhance the applications available analytics. Digital sensing technology offers expanded data that can take proven and dependable sensing methods to new horizons.

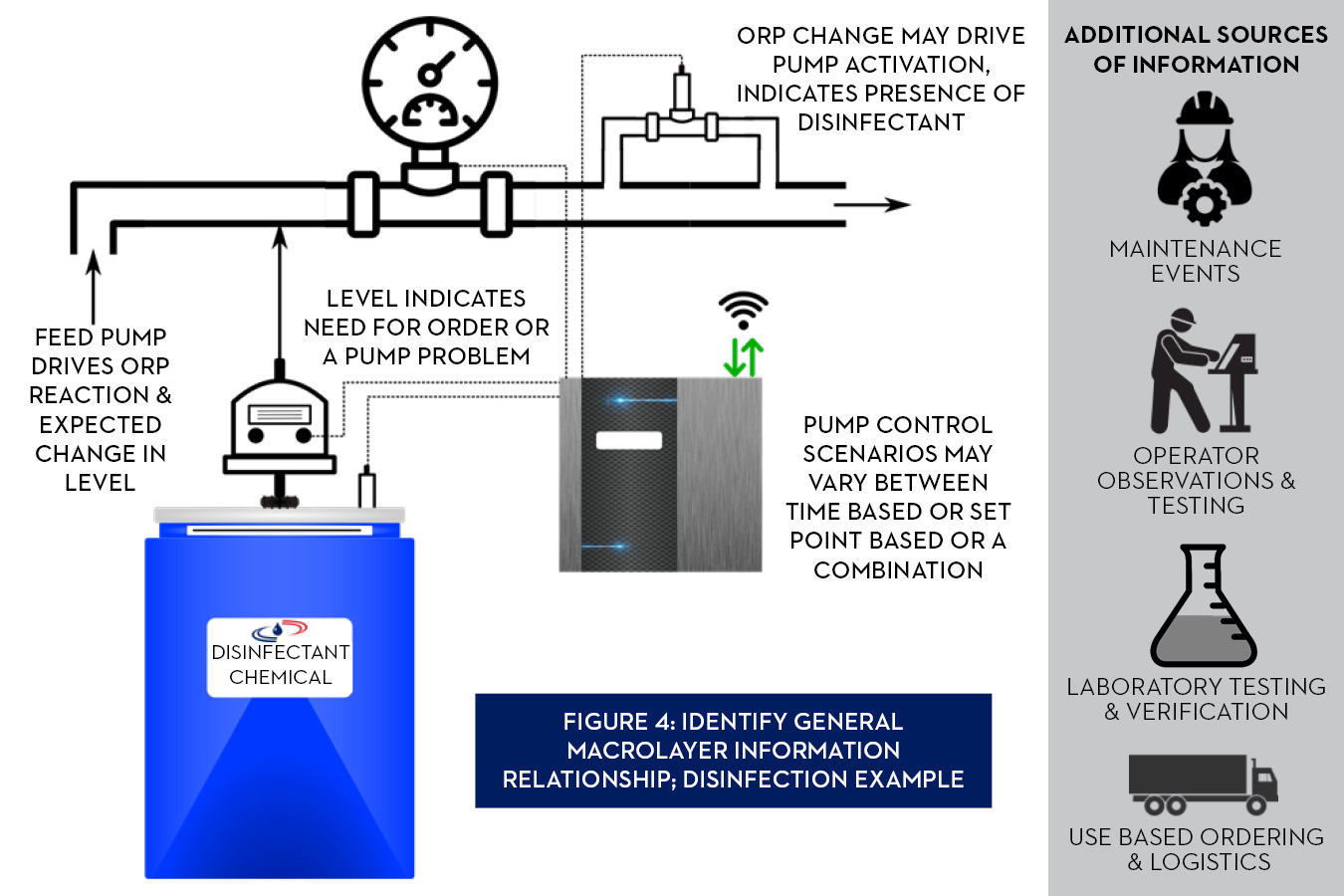
Step 4: Identify Macrolayer Information Relationships
In any application, there are interdependencies in the control application itself and the outside, operational relationships. These relationships are beneficial as intelligence can be built to confirm the control system is operating as expected or check effectiveness of the application against maintenance programs or laboratory analyses. In Figure 4: if the system identifies the chemical feed pump is running, but the tank level and ORP are not changing, this could indicate a problem with the pump. Adding information sources from operations opens even more opportunities to apply intelligence such as, periodic laboratory testing might indicate an increase in certain metals that interfere with the ORP reading; causing an analysis of other control methodologies.
Step 5: Define Relationship Interdependencies
The last step is to fully define the relationships identified in step 4 by determining the specifics surrounding the relationships, along with time considerations, how often to process, and what to do with the results. The resulting conditions can be binary in nature, or a list of conditions with corresponding probability. This information is crucial to allow the computing system to either perform a decisive action or make a recommendation. It’s also important to define which conditions may be invalidated by the appearance of others so the systems can make clearer and more concise decisions.
What’s Next?
Utilizing technology to turn data into intelligent action is relatively young and the benefits are just emerging. As society expands the use of AI and ML into industrial business operations many opportunities will develop to save time or money, increase production, identify and mitigate risks, or make operations safer. No one can say for certain exactly how the benefits will play out over time. As the integration of technology iterates, society will become more comfortable with its ability to make intelligent decisions. We each play a role in ensuring the technology is utilized responsibly; augmenting human intelligence, not replacing it.
Whether the process discussed in this article is utilized or not, I hope that you have an understanding of the depth of thought that is required to enable intelligent decisions from technology.
Various technology services now exist to provide intelligent processing of data. However, developing the intelligence requires collaborative human interaction across multiple disciplines. Engaging a technology team or data scientist will allow you to take the information and context discussed here to build the complex algorithms and network of conditions that will be loaded into the computing services for implementation.
In the next article in this series, we’ll discuss a specific business case for how intelligent technology might develop to impact current issues facing the industrial water treatment sector.